![]()
Managing Files and Folders
What is a data lake? It is just a bunch of files organized by folders. Keeping these files organized prevents your data lake from becoming a data swamp. Today, we are going to learn about a python library that can help you.
Business Problem
Our manager has given us weather data to load into Microsoft Fabric. We need to create folders in the landing zone to organize these files by both full and incremental loads. How can we accomplish this task?
Technical Solution
This use case allows data engineers to learn how to programmatically manage files and folders with the Microsoft Spark Utilities library. The following topics will be explored in this article (thread).
- drop hive tables
- remove folders
- create folders
- move files
- copy files
- write files
- full load strategy
- incremental load strategy
Architectural Overview
The architectural diagram shows how folders are used to organize the data into quality zones. This is sometimes referred to as a medallion lakehouse architecture.
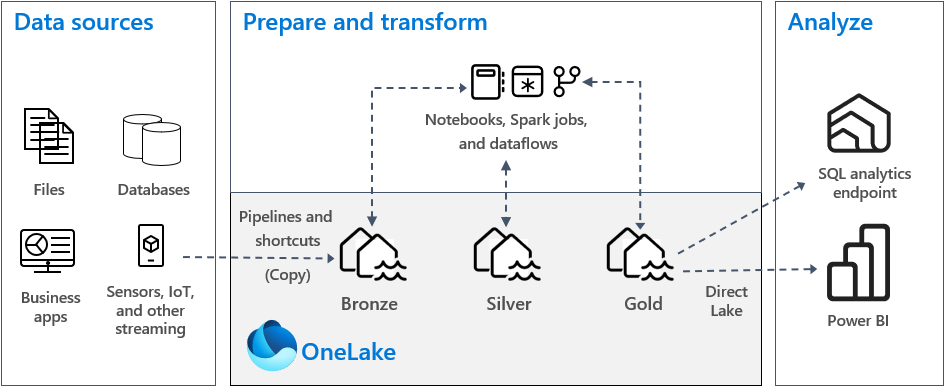
In practice, I have seen an additional quality zone called raw be used to stage files in their native format before converting to a delta file format. Please note, the lake house uses either shortcuts or pipelines to get files into the lake. We will talk more about bronze, silver and gold zones when I cover full and incremental loading later in this article.
Data Lake Cleanup
One great property of a data lake is the fact that it can always be torn down from a current state and rebuilt from the source files. We are going to remove tables and folders from the prior lesson at this time.
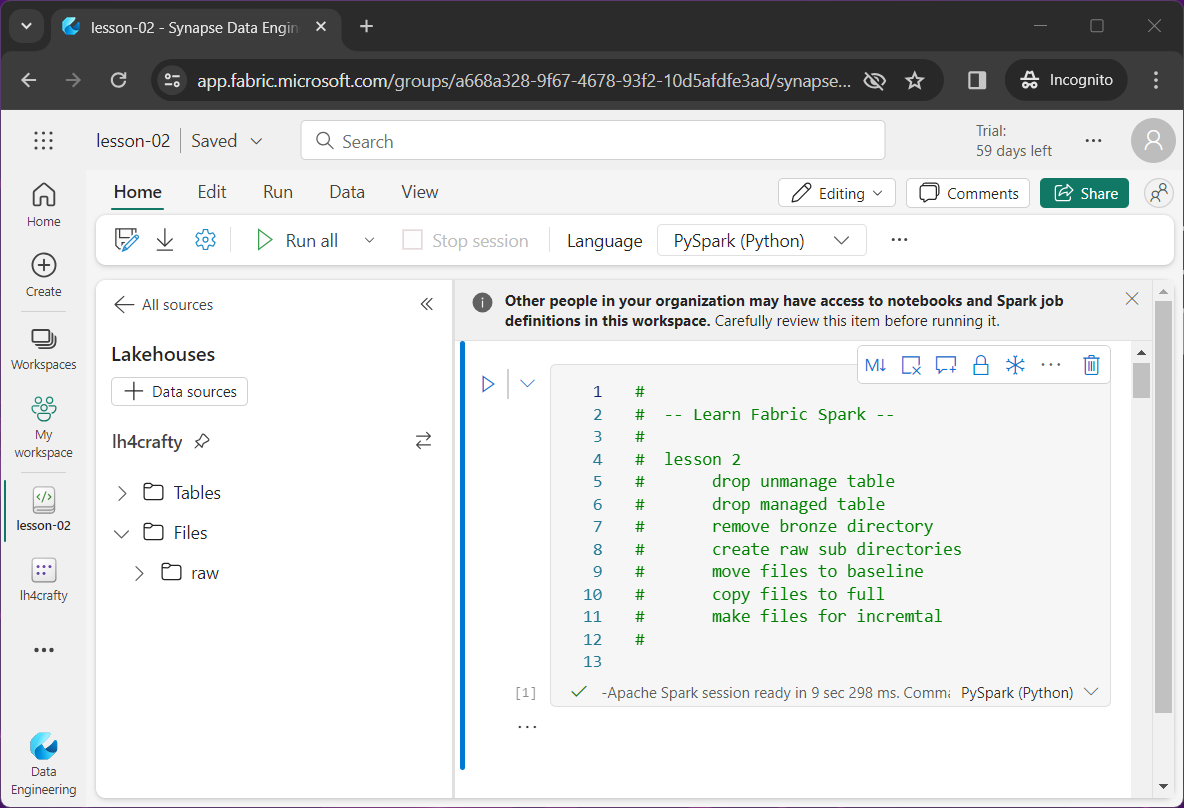
The above image shows the PySpark notebook for lesson 2 loaded into the lake house explorer. The first two tasks involve the execution of Spark SQL to drop tables from the hive catalog.
|
1 2 3 4 5 6 |
%%sql -- -- drop unmanaged (external) table -- drop table if exists unmanaged_weather; |
The above snippet drops the unmanage table while the below snippet drops the managed table.
|
1 2 3 4 5 6 |
%%sql -- -- drop managed (internal) table -- drop table if exists managed_weather; |
The last task is to remove the folder named bronze. We can use the file system remove command with the recursive flag equal to true. I will be talk about the Microsoft Spark Utilities library in detail shortly.
|
1 2 3 4 5 6 7 8 9 |
# # Remove bronze directory # # location path = "Files/bronze" # remove folder mssparkutils.fs.rm(path, True) |
The image below show that both tables and one folder have been deleted.
We are now ready to re-organize the raw (staging) folder (directory).
Managing Folders
Microsoft has supplied the data lake engineer with the Spark Utilities library. One can use the help method to list all the functions that can be called. Please see image below for details on file system methods (functions).
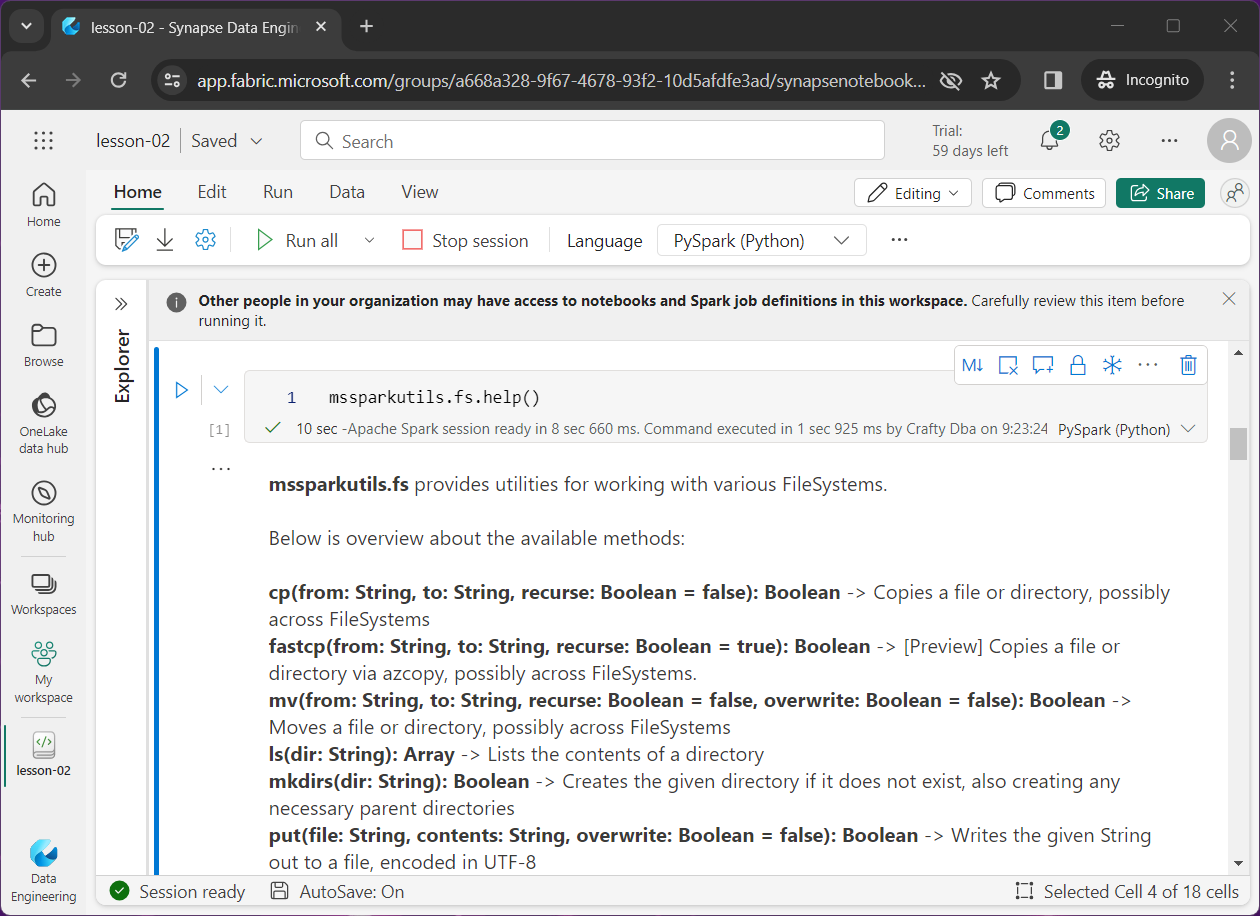
In this section, we are going to focus on the remove and create directory functions in this article. We used the rm function to delete the bronze directory in the prior sections.
We want to organize and/or create data in the following folders.
- raw/baseline – the original weather files
- raw/full – one week of full weather files
- raw/incremental – high/low temperature files by date folder
The image below shows the final folder structure.
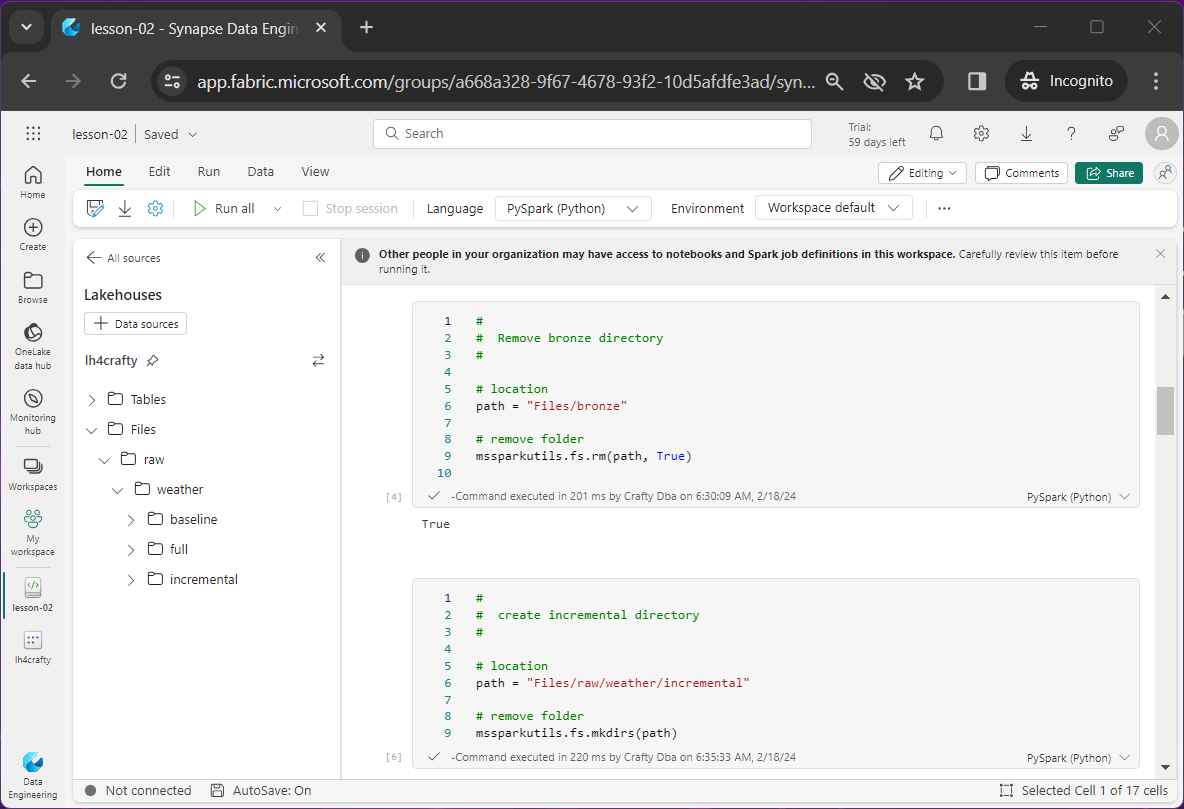
Snippet for baseline folder.
|
1 2 3 4 5 6 7 8 9 |
# # create baseline directory # # location path = "Files/raw/weather/baseline" # remove folder mssparkutils.fs.mkdirs(path) |
Snippet for full folder.
|
1 2 3 4 5 6 7 8 9 |
# # create full directory # # location path = "Files/raw/weather/full" # remove folder mssparkutils.fs.mkdirs(path) |
Snippet for full folder.
|
1 2 3 4 5 6 7 8 9 |
# # create incremental directory # # location path = "Files/raw/weather/incremental" # remove folder mssparkutils.fs.mkdirs(path) |
Creating, renaming and deleting folders can be easily accomplished with the Microsoft Spark Utilities library.
Moving Files
In lesson one, there were three files in the weather directory: high temperature, low temperature and read me. We want to move these files to a sub-folder named baseline
The code below gets a file listing of the weather directory. Then, it iterates thru all files and folders using a for loop. For just files, it moves them to the baseline. Please see the ls and mv functions for details.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# # move files # # locations src_path = "Files/raw/weather" dst_path = "Files/raw/weather/baseline" # get dir listing files = mssparkutils.fs.ls(path) # for each file for file in files: # not dirs if not file.isDir: # src/dst file src_file = src_path + '/' + file.name dst_file = dst_path + '/' + file.name # debug print(src_file) print(dst_file) print("") # move files mssparkutils.fs.mv(src_file, dst_file) |
This is a-lot of code to move just three files. The power of programming file actions is when you have to deal with hundreds if not thousands of files.
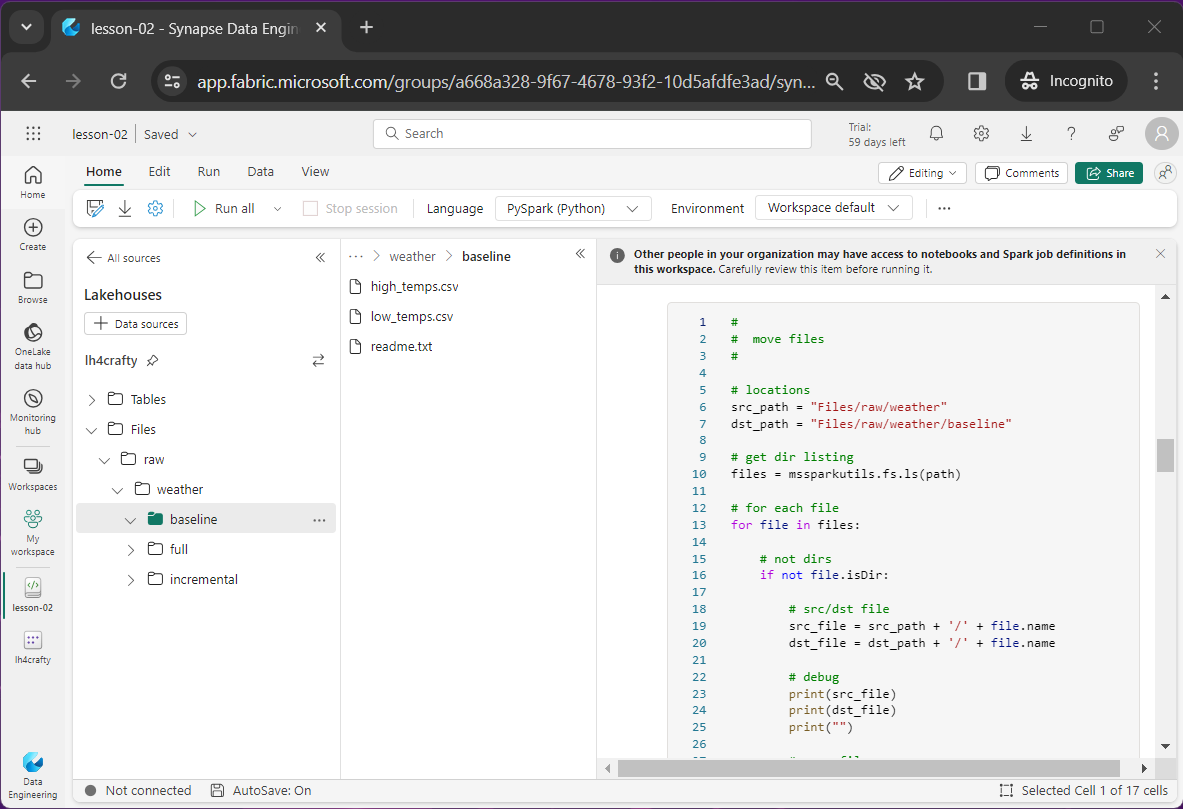
The above image shows the originally upload data files moved to the baseline directory.
Full Load
In lesson 3, I am going to talk about how to load the bronze and silver tables for a full load pattern. For instance, the product list for a company is usually finite and static. For drug companies, how many times do they come up with a new drug?
To simulate this pattern with the weather data set, we want to create one week of folders. I am using the last week in the data set which represents September 24th to the 30th. Each folder will have the complete data file for both high and low temperatures.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
# # create full copies # # source path src_path = "Files/raw/weather/baseline" # destination path dst_path = "Files/raw/weather/full" # one week i = 1 while i < 8: # get day as int d = i + 23 # get date as sortable string s = '201809' + str(d).rjust(2, "0") # debug # print(dst_path + '/' + s) # make sub dir mssparkutils.fs.mkdirs(src_path) # for each file files = ['high_temps.csv', 'low_temps.csv'] for file in files: # src/dst files dst_file = dst_path + '/' + s + '/' + file src_file = src_path + '/' + file # make sub dir mssparkutils.fs.cp(src_file, dst_file) # debug print(src_file) print(dst_file) print('') # increment day i += 1 |
The above code uses both the mkdirs method to create a sub-folder for each day as well as the cp method to copy the data files from the baseline directory to the daily folder. Additionally, I choose to use two different forms of iteration: a while loop and a for loop.
The image below shows the completed task. Seven new folders have been created and fourteen files have been copied.
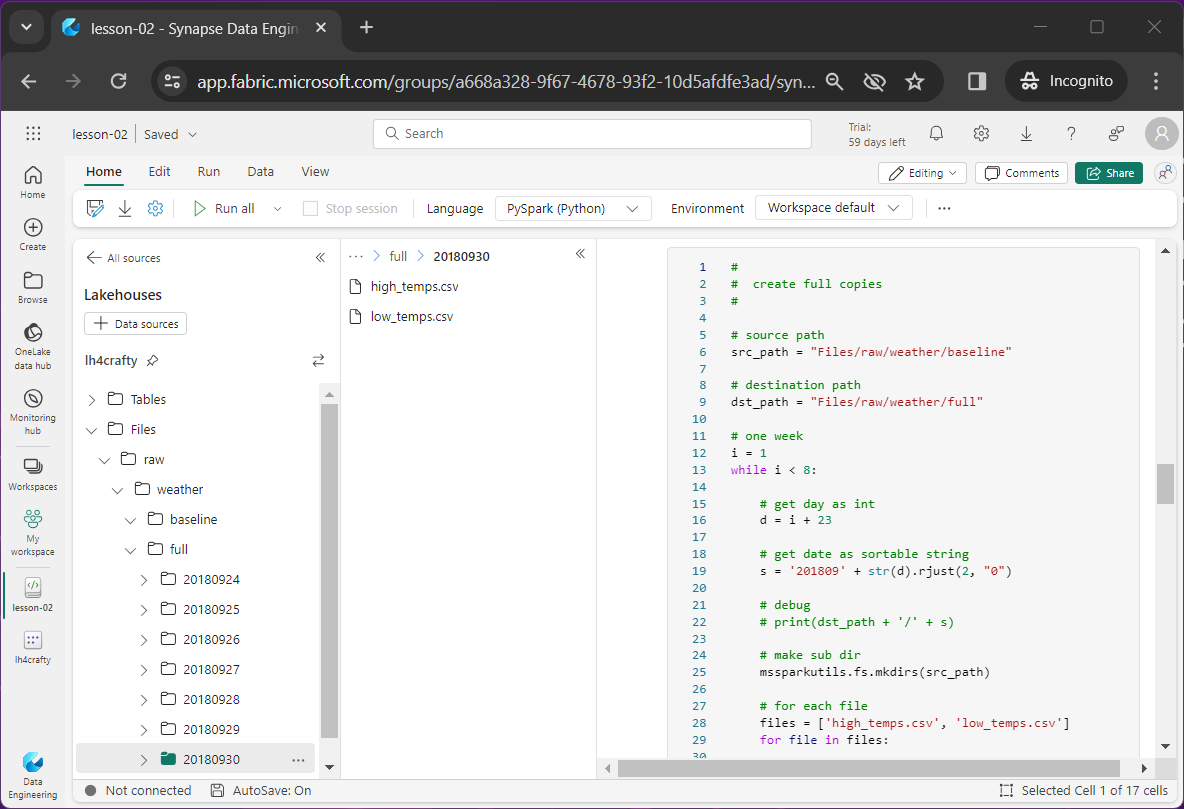
Incremental Load
In lesson 3, I am going to talk about how to load the bronze and silver tables for a incremental load pattern. This is a very common pattern for large datasets. Let’s make believe we are getting the orders from the Amazon website on a given day. That is a very large number of records. If we had a business requirement to have two years of data in the lake at a given point in time, a full load pattern would require moving stale data over and over again.
Just remember, with a incremental load pattern, there is also a historical load component. For instance, we might create 104 data files and each file would contain a week of orders. This would seed our data lake with historical data. Going forward, we would just upload a single days worth of orders.
Now that we have the concept, let’s work on breaking down the high temperature and low temperature data files into a single file per day. Each file will have a single row. We would never do this in the real life, but it is a good example of working with a large set of folders and files.
|
1 2 3 4 5 6 7 8 9 |
# # load high temp data # # location path = "Files/raw/weather/baseline/high_temps.csv" # read file df_high = spark.read.format("csv").option("header","true").load(path) |
|
1 2 3 4 5 6 7 8 9 |
# # load low temp data # # location path = "Files/raw/weather/baseline/low_temps.csv" # read file df_low = spark.read.format("csv").option("header","true").load(path) |
The above code creates two DataFrames, one for high temps and one for low temps. The below code creates our incremental files. It uses the fact that the data files have matching rows by position on date value. Thus, for a given row regardless of file, we have the same date.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
# # create incremental copies # # base of path root = "Files/raw/weather/incremental" # record count c = df_low.count() # convert df to list l = df_low.collect() # convert df to list h = df_high.collect() # static header = 'date,temp' # for each row for r in range(c): # low temp - date, temp, folder, contents d = l[r][0] t = l[r][1] f = d.replace("-", "") contents = f'{header}\r\n{d},{t}\r\n' # make sub dir path = root + '/' + f mssparkutils.fs.mkdirs(path) # write low temp file print(contents) path = root + '/' + f + '/low_temps.csv' mssparkutils.fs.put(path, contents, True) # high temp - date, temp, folder, contents d = h[r][0] t = h[r][1] f = d.replace("-", "") contents = f'{header}\r\n{d},{t}\r\n' # write high temp file print(contents) path = root + '/' + f + '/high_temps.csv' mssparkutils.fs.put(path, contents, True) |
The devil is in the details.
The collect() method converts the DataFrame to a list. For each row, we extract the date and remove any delimiters. In the end, we have a sortable folder name that represents year, month and day. The mkdirs method is used to create a directory. The header line for the files is static and the row if data is retrieved from our lists. We write out the daily file using the put method from the file system class.
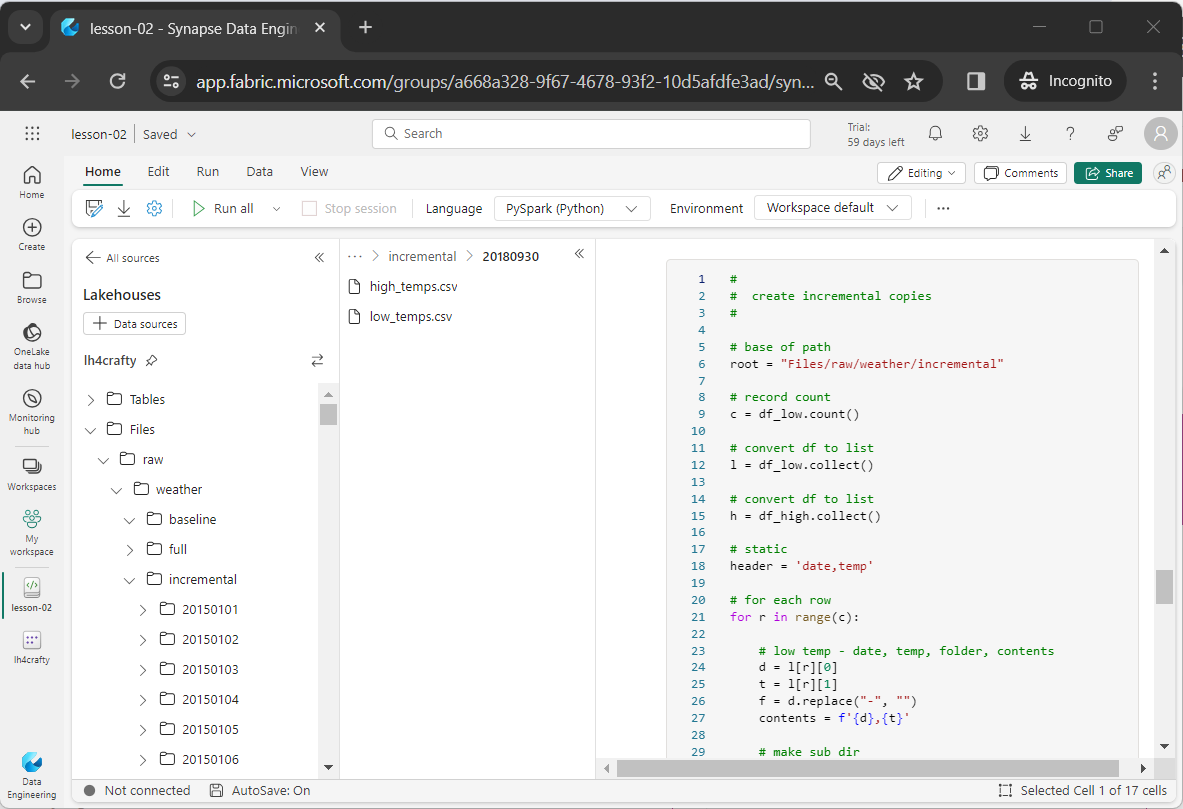
The above image shows the start of the daily folders for incremental data.
Testing
The most important part of any coding assignment is testing.
|
1 2 3 4 5 6 |
# # show full load data # df = spark.read.format("csv").option("header","true").load("Files/raw/weather/full/20180930/high_temps.csv") display(df) |
The above code reads in the latest full load file for high temperatures. The below image shows the output data is scrollable.
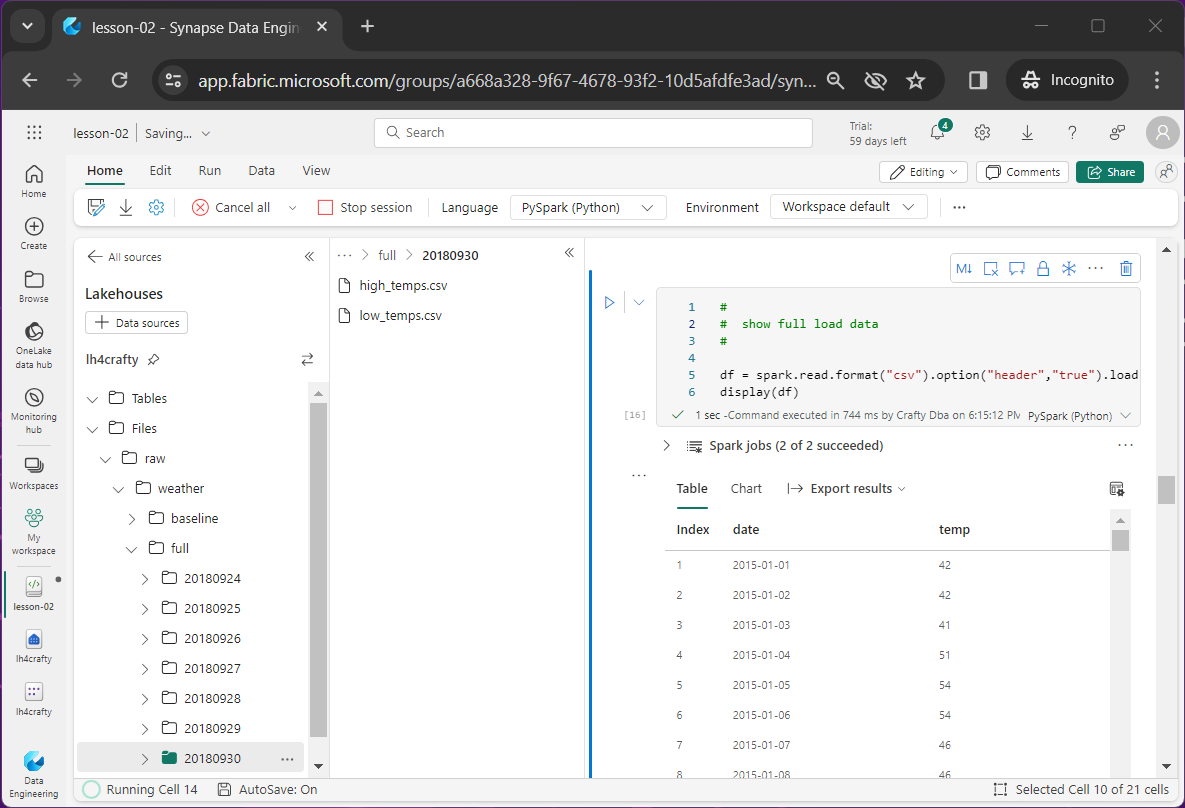
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# # show incremental data, load two files at once # # library from pyspark.sql.functions import * # high temp record df1 = spark.read.format("csv").option("header","true") \ .load("Files/raw/weather/incremental/20180930/high_temps.csv") \ .withColumn('desc', lit('high')) # low temp record df2 = spark.read.format("csv").option("header","true") \ .load("Files/raw/weather/incremental/20180930/low_temps.csv") \ .withColumn('desc', lit('low')) # combine records df3 = df1.unionAll(df2) display(df3) |
The screen shot shown below captures the output of this code snippet.
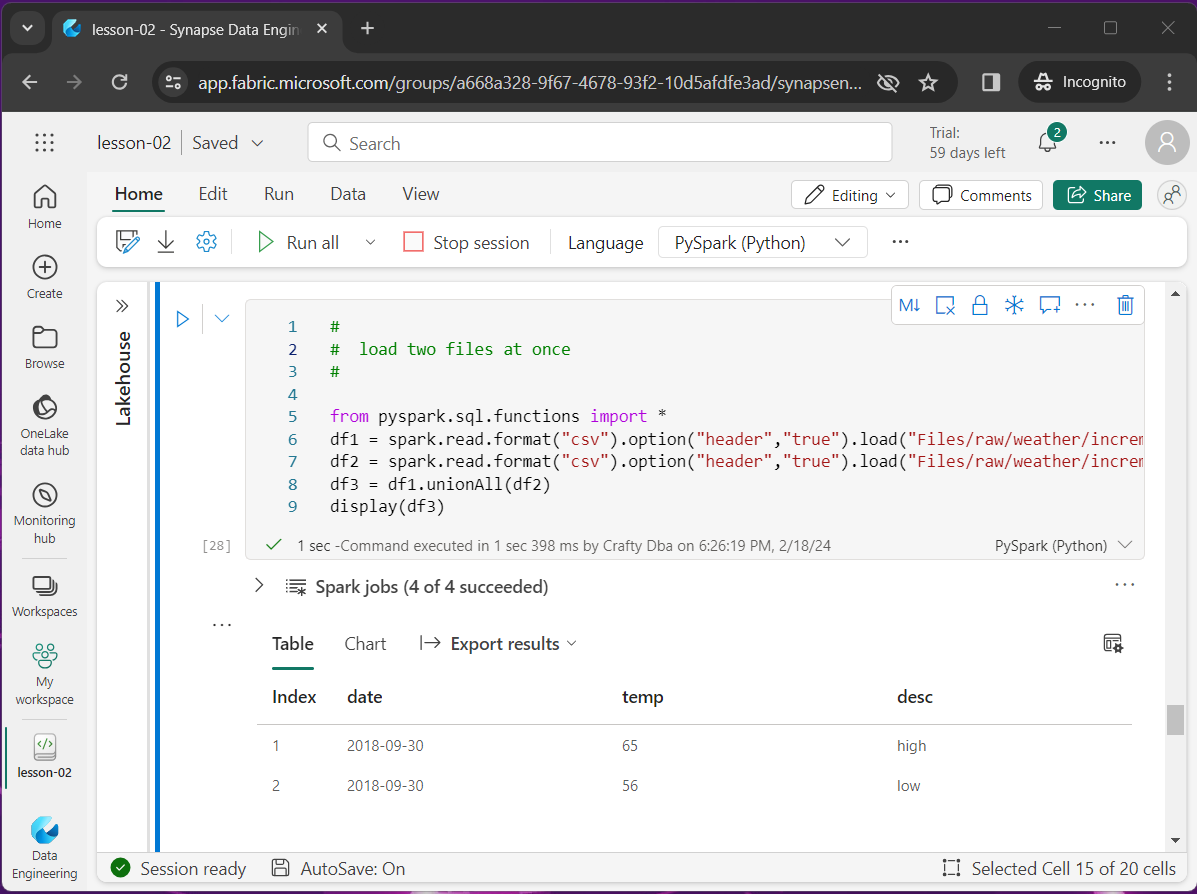
Issues
It is very important to test. I am not going to go over two issues that I have found with Microsoft Fabric.
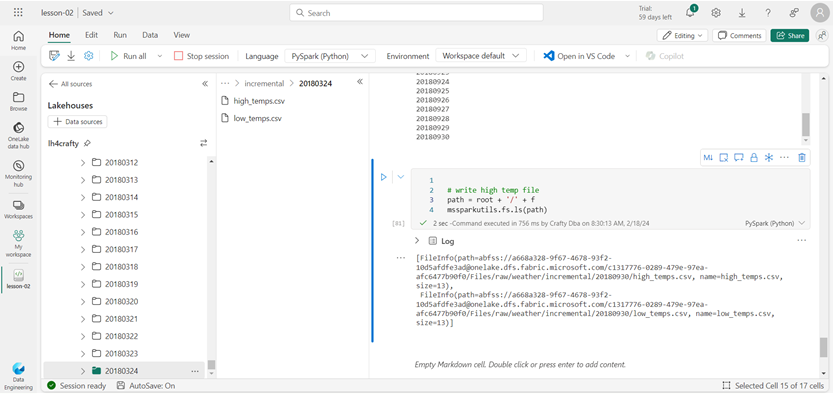
First, when creating a large number of folders and files, the lake house explorer stops refreshing. The image below shows that the last incremental folder is dated 20180324. However, we can list the last directory we created using the ls command. It was dated 20180930.
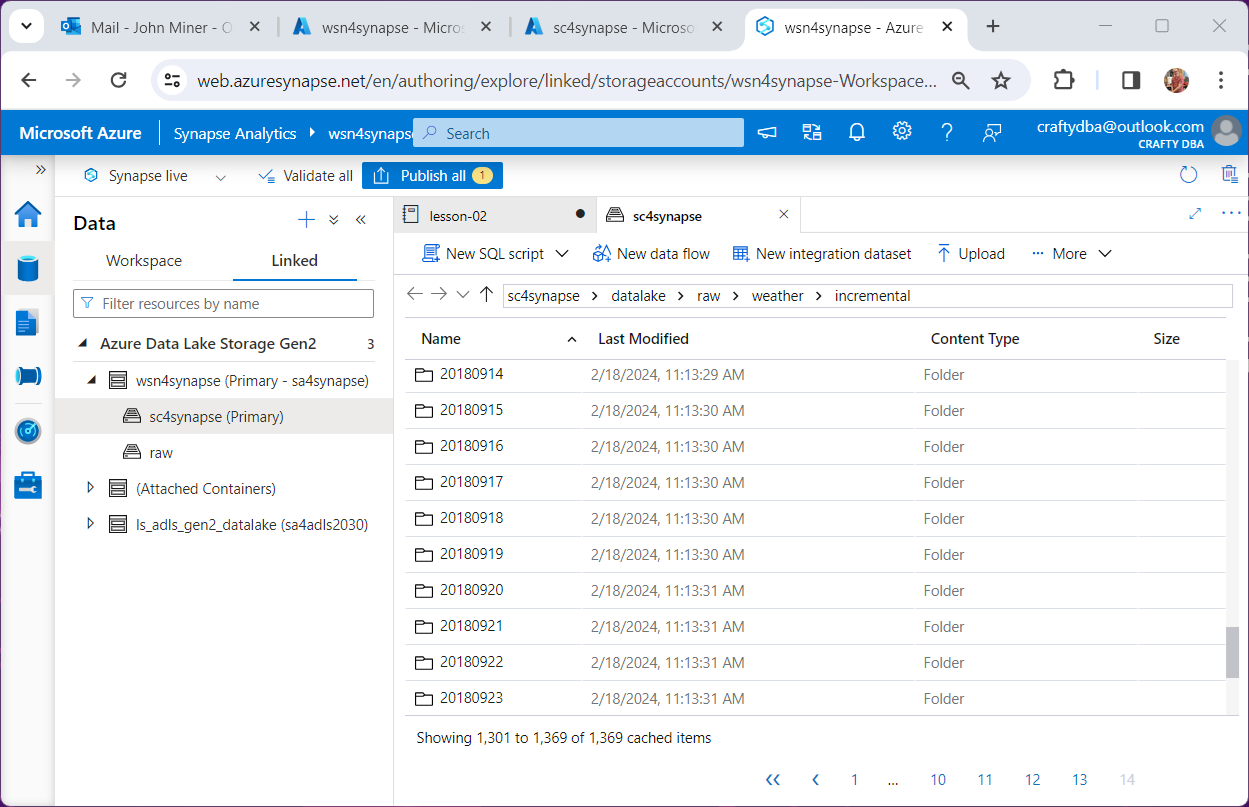
Since Fabric has many components that were in Azure Synapse, I tried reproducing this bug in that environment. Fabric uses a scrollable list and Synapse uses a paging method. We can see Synapse does not have this issue.
In fact, I think it is some type of refresh or timing bug. Much later, I logged out and logged back in. Low and behold, the folders showed up.
If you look hard enough at the Fabric Graphical User Interface (GUI), you can see parts of Office 365 and Power BI. Second, this historical foundation might be the root cause of the second issue.
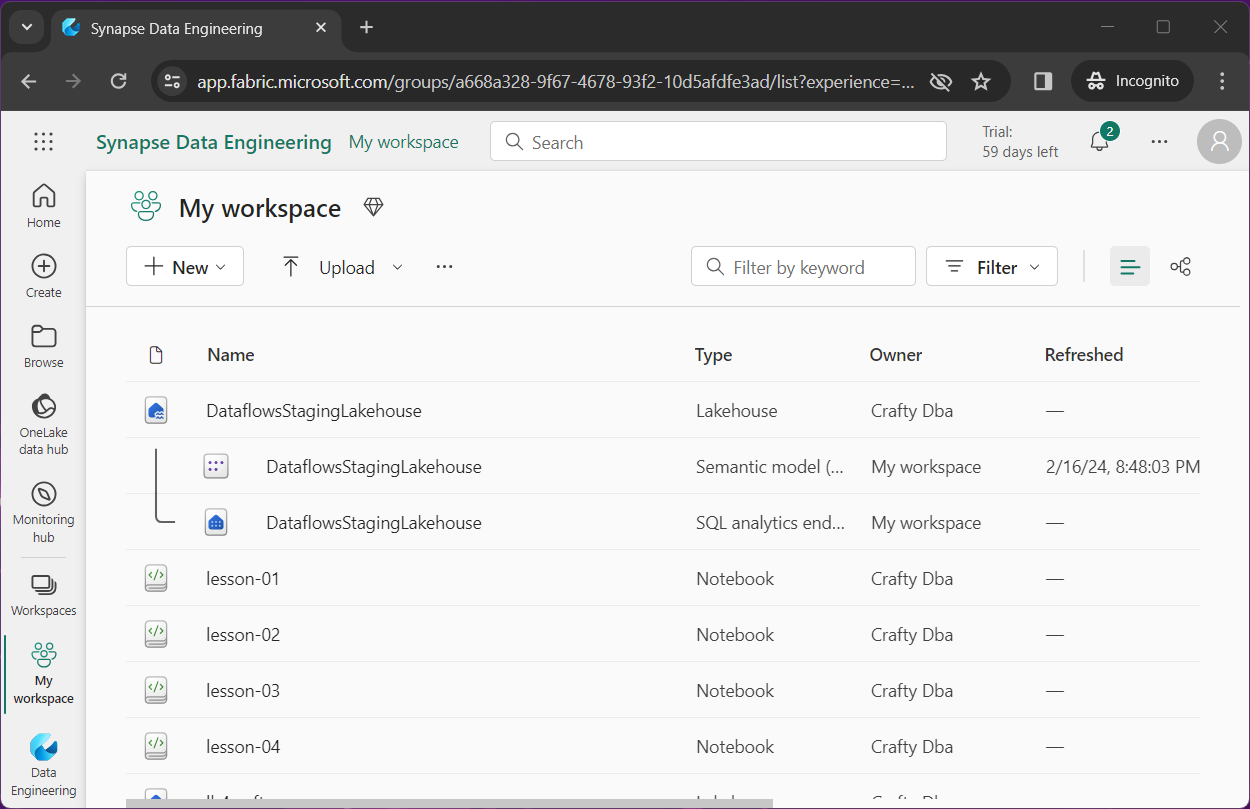
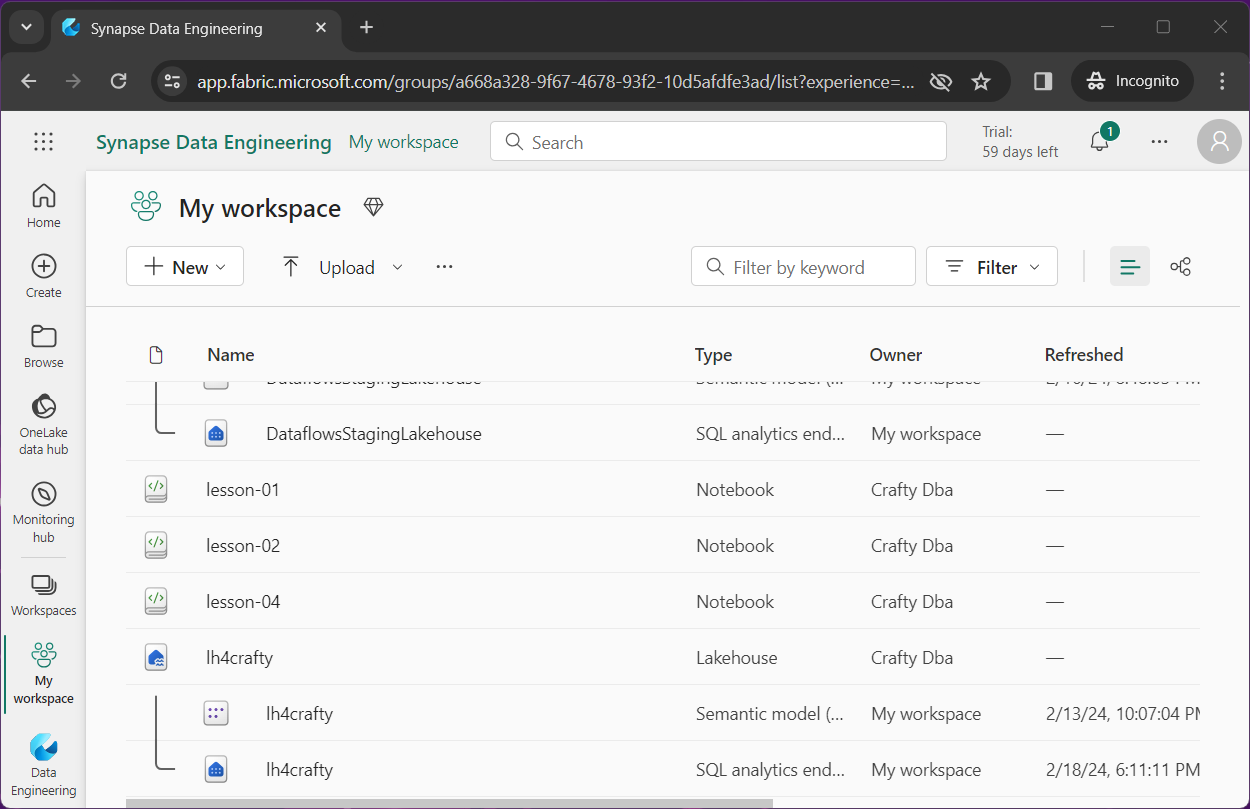
The above image shows that I saved the notebook for lesson-02 as lesson-03 and lesson04. The below image shows the deletion of the notebook named lesson-03.
 \
\
If I try to rename lesson-04 as lesson-03, I get an error message stating the notebook already exists.
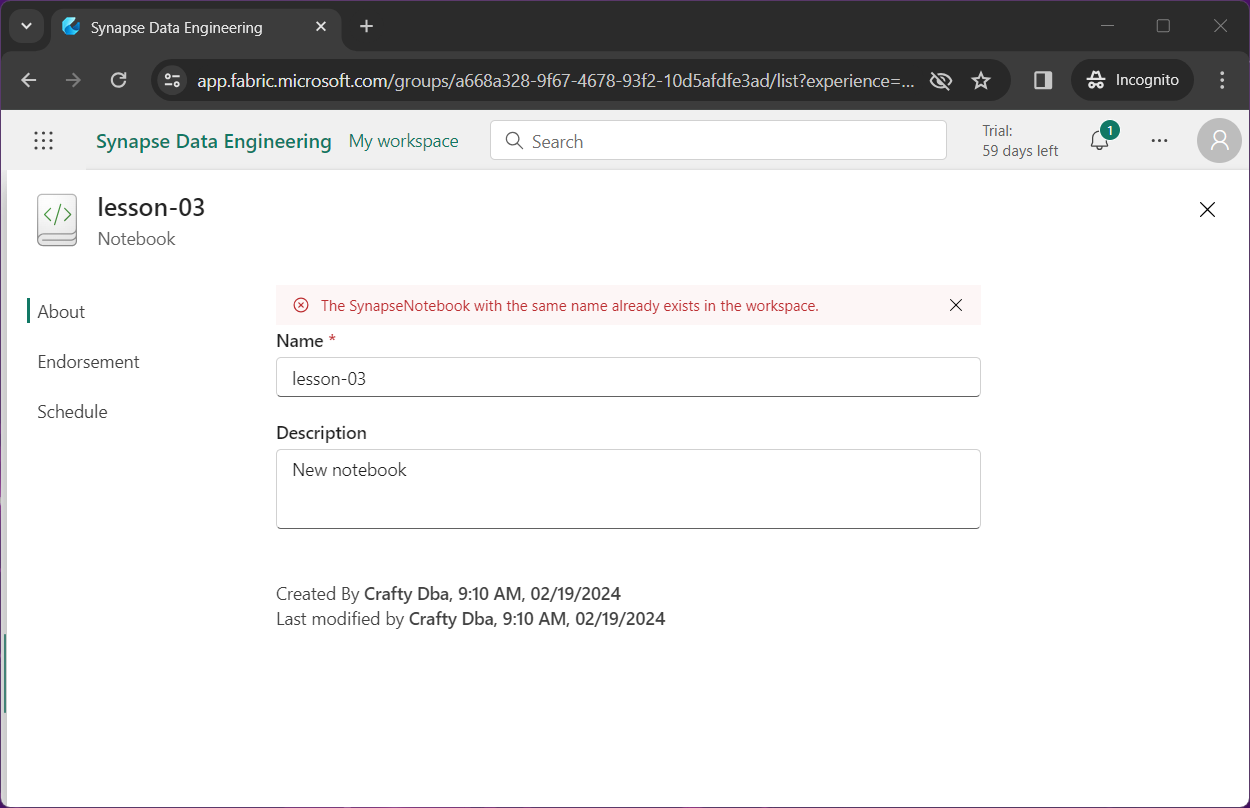
This is a feature in Power BI in which an object is soft deleted. Unfortunately, the system has not caught up with the fact that the file is now gone and the name can be re-used. Again, if you log into the system minutes later, you will be able to rename the file.
Summary
Fabric supplies the data engineer with the Microsoft Spark Utilities library. Today, we focused on some of the functions that work with both folders and files. Writing code for large scale folder or file changes is the best way to go. Who wants to create and upload a couple thousand files?
Just remember that the Fabric service went to General Availability in November 2023. Engineers are starting to use the system and suggest changes make it better. In general, I love the one lake concept of Fabric. Enclosed is the zip file with the data files and Spark notebook.