I am going start a series of articles describing how information is stored and organized in a Microsoft SQL Server database. Today, I am going to talk about the File Header Page.
Every database is defined by at least two file types. The first file type is one primary (*.mdf) data file with zero or more optional secondary (*.ndf) data files. The second file type are log (*.ldf) files. We will be looking at the primary data file during these talks.

All of the information is a gleamed from SQL Server 2008 Internals book by Kalen Delaney. If it is not on your bookshelf, I suggest you go out and by a copy. The online MCM training videos from Paul Randal are also an excellent resource.
Before I get into the nitty gritty details of storing data, we need to have a sample database to play with. I pulled apart the [pubs] sample database supplied with SQL Server 2000 from MSDN. While this database is simplistic in nature, it is easy to work with.
Enclosed is the script to create the [pubs] database with the [title] table. There is one clustered primary key defined on [title_id] field and one non-clustered index specified on the [title] field.
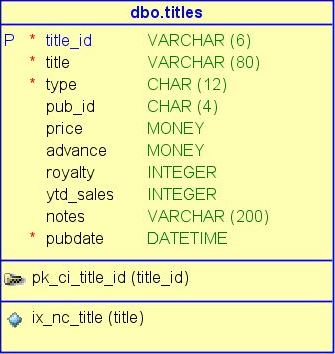
If we execute the ‘sp_helpdb pubs’ command, we can see that our sample database takes 20 megabytes of total space, the database id is 36 on my laptop and the database has two files, primary data file and log file.
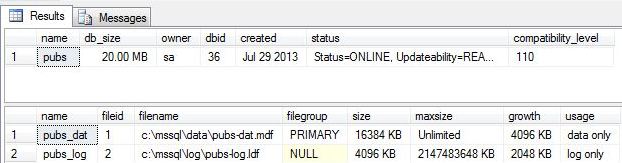
Many of the DBCC commands that I will be introducing use file number as a parameter. Please note that the primary data file is id 1.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- -- Show the file header page -- -- 1 - file header page dbcc fileheader ('pubs', 1); -- enable output to client dbcc traceon (3604, -1); -- 2 - file header page dbcc page (pubs, 1, 0, 3); -- disable output to client dbcc traceoff (3604, -1); |
There are two quick ways to dump the file header page.
The first way is to call the DBCC FILEHEADER undocumented command with the name of the database and the file. Why pass a file number? Every primary and/or secondary data file contains this page type.

The full first output can be viewed here.
Here are some interesting things to note: file id, logical file name, binding guid, and backup lsn to name a few. The actual size and growth settings are number of pages. In our [pubs] database, 2048 x 8 K pages equals a 16 MB data file. A negative one means unlimited growth or size.
The second way is to use trace flag 3604 to allow output from the DBCC PAGE command to be seen in our query window. Next, call the undocumented command with the name of the database, the file number, the page number, and the display type. The file header is on page zero in the database. Last but not least, clean up after yourself by turning off the trace flag.
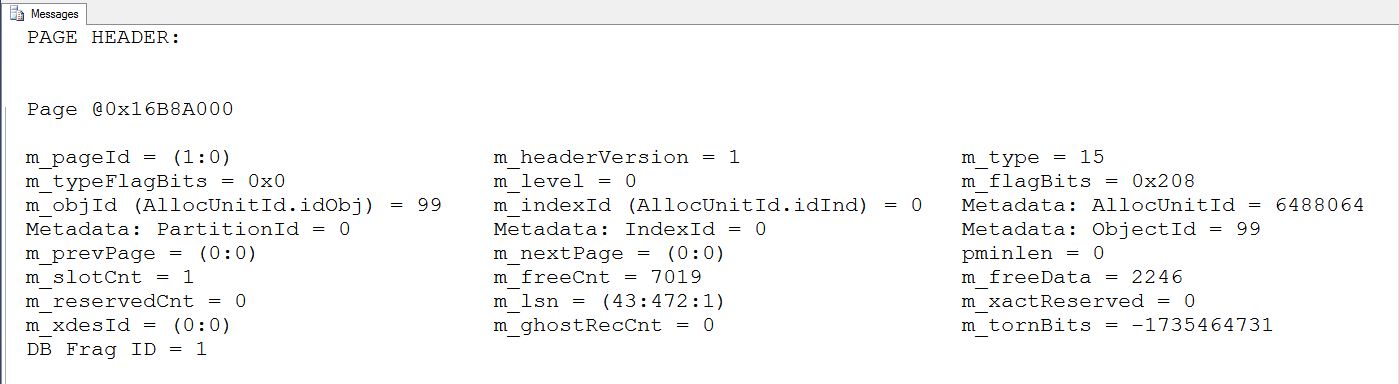
Get used to the second set of commands since this technique can be used to dump any page in the data file.
The full second output can be viewed here.
Looking closely at the output, we notice that each page has a page header. This page header is always 96 bytes in length. The m_pageId shows that we are on file 1, page 0. The m_type is marked as a 15 or a file header page. The m_slotcnt means we only have 1 record. The m_freeCnt tells us that we have 7019 bytes of usable space free on the page.
The file header page is very critical. If it gets corrupted on the primary data file, you will have to restore the page or file from a backup.
Next time I will be talking about the Database Boot Page. I will be going into more detail about extents, pages, and how different pages are organized as we explore them.
